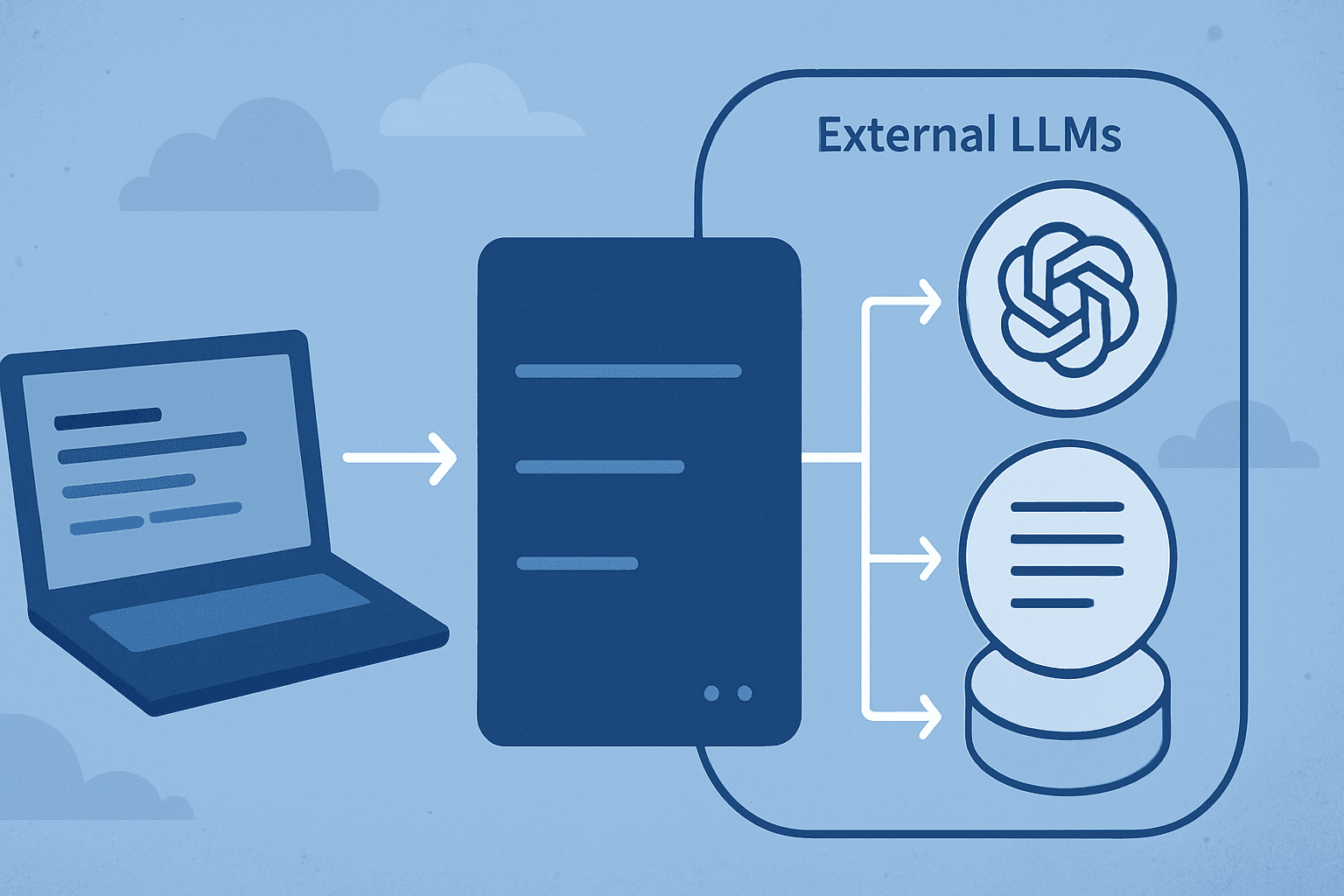
Unlocking Precision: Advanced Distance Metrics for Superior Image Search

When developing image search apps, it is essential to consider how we determine the similarity between images. Selecting the appropriate distance measurement can greatly affect the precision and significance of your search outcomes.
In a previous post on (https://tjgokken.com/vector-image-search-with-azure-ai), we created a console application that organizes images by their tags. In that application, we utilized the Euclidean distance, which measures the direct distance between two points within a feature space. Although Euclidean distance is effective in numerous cases, it may not be the optimal choice in complex or high-dimensional data sets.
In this article we will delve into advanced vector distance metrics like Manhattan distance, Chebyshev distance, and Mahalanobis distance, examining how they can enhance image search in specific situations. By being aware of the pros and cons of each metric, you can improve your decisions and adjust your image search algorithms to ensure they are as accurate and relevant as possible.
A Quick Recap: Euclidean Distance
The Euclidean distance is easy to understand and straightforward. It calculates the direct distance between two points in three-dimensional space.
This measure is effective for data with few dimensions and when the characteristics of images have comparable scales. However, when your dataset becomes more complex or when you are dealing with images with varying feature importance or correlations, Euclidean distance might not provide the most accurate results.
Fortunately, there are alternative distance measures that may help solve these problems.
Manhattan Distance
Manhattan Distance is a measure of distance between two points in a grid based on horizontal and vertical movements only.
Manhattan distance calculates the overall distance between two points by summing the absolute variances of their coordinates. Imagine it as strolling through urban streets where you are limited to moving only in a horizontal or vertical direction.
This distance works well for high-dimensional data or data arranged in grids, like pixels in an image. It's also less affected by outliers than Euclidean distance, making it a good choice when some feature values vary a lot.
Chebyshev Distance
The Chebyshev distance, known as the L∞ norm, computes the largest difference between any two elements in two vectors. It is frequently used in cases where the primary difference is essential, like in chess where the king can only move one square in any direction.
This distance is useful in situations where one feature stands out more than others. For example, when comparing images with strong contrasts, Chebyshev distance ensures that a big difference in one feature, like brightness, has a bigger impact than smaller differences in other features.
Mahalanobis Distance
The Mahalanobis distance is a complex measure that considers the relationships between variables in the dataset. Unlike Euclidean distance, this method considers relationships between features, making it better suited for data with closely connected features.
This distance is especially useful when features tend to vary together. For example, in an image search, if "water" and "fish" often appear together, Mahalanobis distance takes that into account, leading to smarter and more accurate comparisons, especially for datasets with strong feature correlations.
In an image search app like we built using the Euclidean distance, Mahalanobis distance excels when you have a dataset where certain features are strongly correlated. For instance, if you're comparing wildlife photos, “water” and “fish” might often appear together. By accounting for these correlations, Mahalanobis distance helps the model make smarter comparisons, improving the quality of the search results.
Image Search App (v.2)
Let’s see all of these metrics in action.
In our previous article, we built an application for correctly identifying the type of image we feed into it. Let’s enhance that application with these metrics and see how they differ.
Once we implement the 3 metrics in addition to the Euclidean distance, our code looks like below:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using MathNet.Numerics.LinearAlgebra;
using MathNet.Numerics;
namespace ImageSearchWithDistanceMetrics
{
internal class Program
{
private static readonly string subscriptionKey = "YOUR_COMPUTER_VISION_SUBSCRIPTION_KEY";
private static readonly string endpoint = "YOUR_COMPUTER_VISION_ENDPOINT";
private static async Task Main(string[] args)
{
var client = new ComputerVisionClient(new ApiKeyServiceClientCredentials(subscriptionKey))
{
Endpoint = endpoint
};
// Sample public domain image URLs from Flickr with associated labels
var images = new Dictionary<string, string>
{
{ "https://live.staticflickr.com/5800/30084705221_6001bbf1ba_b.jpg", "City" },
{ "https://live.staticflickr.com/4572/38004374914_6b686d708e_b.jpg", "Forest" },
{ "https://live.staticflickr.com/3446/3858223360_e57140dd23_b.jpg", "Ocean" },
{ "https://live.staticflickr.com/7539/16129656628_ddd1db38c2_b.jpg", "Mountains" },
{ "https://live.staticflickr.com/3168/2839056817_2263932013_b.jpg", "Desert" }
};
// Store the vectors and all unique tags found
var imageVectors = new Dictionary<string, double[]>();
var allTags = new HashSet<string>();
// Extract features for all images and collect all unique tags
var imageTagConfidenceMap = new Dictionary<string, Dictionary<string, double>>();
foreach (var imageUrl in images.Keys)
{
var imageTags = await ExtractImageTags(client, imageUrl);
imageTagConfidenceMap[imageUrl] = imageTags;
allTags.UnionWith(imageTags.Keys); // Collect unique tags
Console.WriteLine($"Extracted tags for {imageUrl}");
}
// Create fixed-size vectors for each image based on all unique tags
foreach (var imageUrl in images.Keys)
{
var vector = CreateFixedSizeVector(allTags, imageTagConfidenceMap[imageUrl]);
imageVectors[imageUrl] = vector;
}
// Perform a search for the most similar image to a query image
var queryImage = "https://live.staticflickr.com/3697/8753467625_e19f53756c_b.jpg"; // New forest image
var queryTags = await ExtractImageTags(client, queryImage); // Extract tags for the new image
var queryVector = CreateFixedSizeVector(allTags, queryTags); // Create vector based on those tags
FindMostSimilarImagePerMetric(queryVector, imageVectors,
images); // Search for the closest match using all metrics
// Perform benchmarking
Benchmark(queryVector, imageVectors);
}
// Extracts tags and their confidence scores from an image
private static async Task<Dictionary<string, double>> ExtractImageTags(ComputerVisionClient client, string imageUrl)
{
var features = new List<VisualFeatureTypes?> { VisualFeatureTypes.Tags };
var analysis = await client.AnalyzeImageAsync(imageUrl, features);
var tagsConfidence = new Dictionary<string, double>();
foreach (var tag in analysis.Tags) tagsConfidence[tag.Name] = tag.Confidence;
return tagsConfidence;
}
// Create a fixed-size vector based on all possible tags
private static double[] CreateFixedSizeVector(HashSet<string> allTags, Dictionary<string, double> imageTags)
{
var vector = new double[allTags.Count];
var index = 0;
foreach (var tag in allTags) vector[index++] = imageTags.TryGetValue(tag, out var imageTag) ? imageTag : 0.0;
return vector;
}
// Manhattan (L1 norm)
private static double ManhattanDistance(double[] a, double[] b)
{
double sum = 0;
for (var i = 0; i < a.Length; i++) sum += Math.Abs(a[i] - b[i]);
return sum;
}
// Chebyshev (L∞ norm)
private static double ChebyshevDistance(double[] a, double[] b)
{
double max = 0;
for (var i = 0; i < a.Length; i++) max = Math.Max(max, Math.Abs(a[i] - b[i]));
return max;
}
// Mahalanobis distance using Accord.NET
private static double MahalanobisDistance(double[] a, double[] b, double[][] vectors)
{
// Compute the covariance matrix using Accord.NET
var covarianceMatrix = ComputeCovarianceMatrix(vectors);
// Compute the inverse of the covariance matrix
var inverseCovarianceMatrix = covarianceMatrix.Inverse();
// Calculate the difference vector
var diff = a.Subtract(b);
// Calculate Mahalanobis distance
var mahalanobisDistance = diff.Dot(inverseCovarianceMatrix.Dot(diff));
return Math.Sqrt(mahalanobisDistance);
}
// Compute covariance matrix using Accord.NET
private static double[,] ComputeCovarianceMatrix(double[][] data)
{
// Get the number of rows and columns
var rows = data.Length;
var cols = data[0].Length;
// Create a rectangular (2D) array
var rectangularData = new double[rows, cols];
// Copy the data from the jagged array into the rectangular array
for (var i = 0; i < rows; i++)
for (var j = 0; j < cols; j++)
rectangularData[i, j] = data[i][j];
// Compute the covariance matrix using Accord.NET
return rectangularData.Covariance();
}
// Find the most similar image for each distance metric
private static void FindMostSimilarImagePerMetric(double[] queryVector, Dictionary<string, double[]> imageVectors,
Dictionary<string, string> imageLabels)
{
var metrics = new Dictionary<string, Func<double[], double[], double>>
{
{ "Euclidean", Distance.Euclidean },
{ "Manhattan", ManhattanDistance },
{ "Chebyshev", ChebyshevDistance },
{ "Mahalanobis", (a, b) => MahalanobisDistance(a, b, imageVectors.Values.ToArray()) }
};
// Find the most similar image for each metric
foreach (var metric in metrics)
{
string mostSimilarImage = null;
var smallestDistance = double.MaxValue;
foreach (var imageVector in imageVectors)
{
var distance = metric.Value(queryVector, imageVector.Value);
if (distance < smallestDistance)
{
smallestDistance = distance;
mostSimilarImage = imageVector.Key; // Keep track of the image URL or ID
}
}
// Check if the most similar image is found
if (mostSimilarImage != null && imageLabels.ContainsKey(mostSimilarImage))
Console.WriteLine(
$"Using {metric.Key} distance, this picture is most similar to: {imageLabels[mostSimilarImage]}");
else
Console.WriteLine($"No match found using {metric.Key} distance.");
}
}
private static void Benchmark(double[] queryVector, Dictionary<string, double[]> imageVectors)
{
var metrics = new Dictionary<string, Func<double[], double[], double>>
{
{ "Euclidean", Distance.Euclidean },
{ "Manhattan", ManhattanDistance },
{ "Chebyshev", ChebyshevDistance },
{ "Mahalanobis", (a, b) => MahalanobisDistance(a, b, imageVectors.Values.ToArray()) }
};
// Benchmark each metric
foreach (var metric in metrics)
{
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
foreach (var imageVector in imageVectors)
{
metric.Value(queryVector, imageVector.Value);
}
stopwatch.Stop();
Console.WriteLine($"{metric.Key} distance computation time: {stopwatch.ElapsedMilliseconds} ms");
}
}
}
}
Now, let's see how we put these additional metrics into practice.
The Manhattan distance is calculated by adding up the absolute differences between each pair of elements in the vectors. The code achieves this by going through every item in vectors a and b, finding the absolute difference for each pair, and then adding up all the differences.
private static double ManhattanDistance(double[] a, double[] b)
{
double sum = 0;
for (int i = 0; i < a.Length; i++)
{
sum += Math.Abs(a[i] - b[i]); // Add absolute difference between corresponding elements
}
return sum;
}
The Chebyshev distance is the maximum absolute difference between the corresponding elements of two vectors. We implement Chebyshev distance by iterating through the vectors, calculating the absolute differences, and keeping track of the largest difference.
private static double ChebyshevDistance(double[] a, double[] b)
{
double max = 0;
for (int i = 0; i < a.Length; i++)
{
max = Math.Max(max, Math.Abs(a[i] - b[i])); // Track the maximum absolute difference
}
return max;
}
Mahalanobis distance considers the covariance between vector features to account for correlations between them. Calculating the Mahalanobis distance is more difficult as it involves the calculation of the dataset's covariance matrix and its inverse.
Also, note that we used Accord.NET math library for the calculation of the covariance.
private static double MahalanobisDistance(double[] a, double[] b, double[][] vectors)
{
// Compute the covariance matrix using Accord.NET
var covarianceMatrix = ComputeCovarianceMatrix(vectors);
// Compute the inverse of the covariance matrix
var inverseCovarianceMatrix = covarianceMatrix.Inverse();
// Calculate the difference vector
var diff = a.Subtract(b);
// Calculate Mahalanobis distance
var mahalanobisDistance = diff.Dot(inverseCovarianceMatrix.Dot(diff));
return Math.Sqrt(mahalanobisDistance);
}
// Compute covariance matrix using Accord.NET
private static double[,] ComputeCovarianceMatrix(double[][] data)
{
// Get the number of rows and columns
var rows = data.Length;
var cols = data[0].Length;
// Create a rectangular (2D) array
var rectangularData = new double[rows, cols];
// Copy the data from the jagged array into the rectangular array
for (var i = 0; i < rows; i++)
for (var j = 0; j < cols; j++)
rectangularData[i, j] = data[i][j];
// Compute the covariance matrix using Accord.NET
return rectangularData.Covariance();
}
When we run our app, we get the following results:
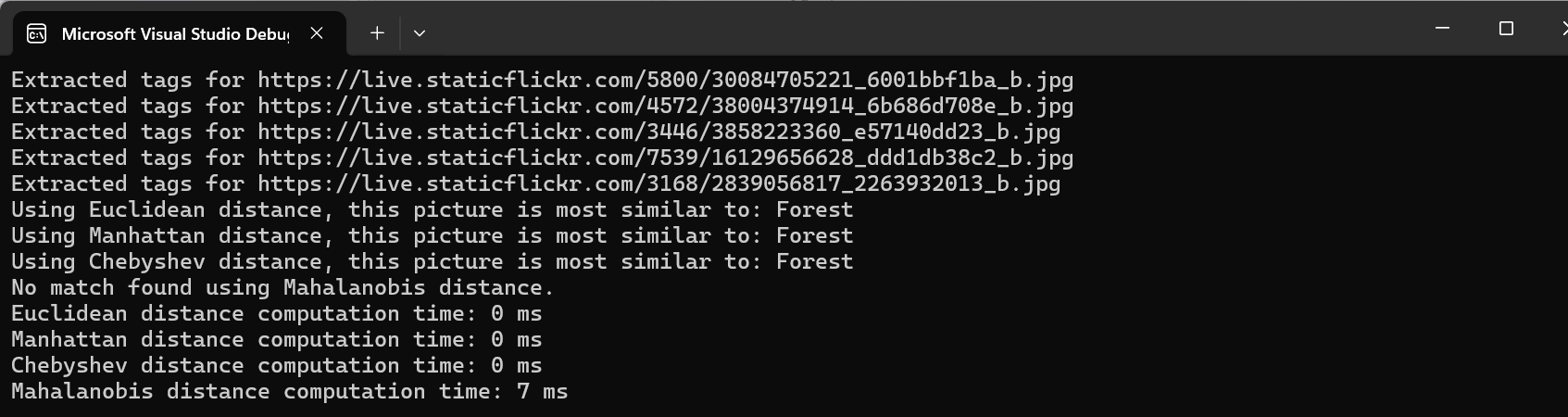
As our dataset is very small, the time benchmark does not give us much of anything, however, we can see that all of the other models correctly identified the image… except Mahalanobis.
There may be several reasons for that but usually this is because of the small number of images (5) we have in our dataset. Increasing the dataset may help, as Mahalanobis distance performs better with larger datasets where feature correlations can be more accurately captured. This would allow the metric to make smarter comparisons, improving the quality of the search results.
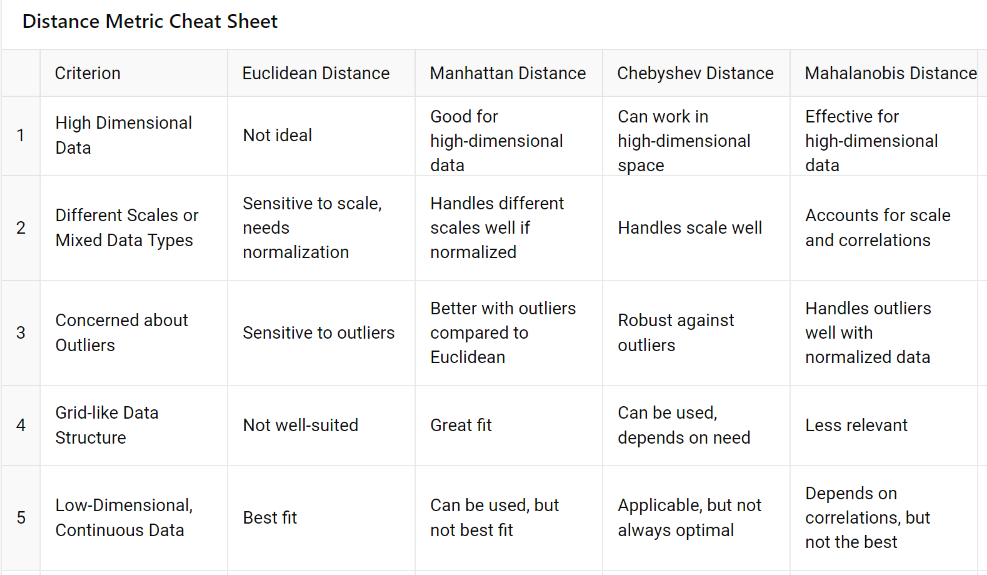
When to Use Which Distance Metric?
Here’s a quick guide to help you choose the right distance metric for your image search:
Euclidean Distance: Use it when you have low-dimensional, uncorrelated data or when all features are equally important.
Manhattan Distance: Ideal for high-dimensional data or when comparing images in a grid-like structure (e.g., pixel-based images).
Chebyshev Distance: Best for scenarios where the maximum difference in any one feature is critical to your search.
Mahalanobis Distance: Perfect for high-dimensional, correlated data, especially when certain features have stronger relationships than others.
Here is a quick cheat sheet summarizing the information above:
Conclusion: Matching the Metric to the Data
Choosing the correct distance metric in image search can greatly affect the precision and significance of your outcomes. Although Euclidean distance is often used and straightforward, more sophisticated metrics such as Manhattan, Chebyshev, and Mahalanobis distance can provide improved results with complex, high-dimensional, or correlated datasets.
When refining your image search model, try out various metrics to determine which one fits your dataset and application needs best. Once you have the correct distance measurement established, you can adjust your search algorithm to enhance both accuracy and relevance.
Here is the project source code: https://github.com/tjgokken/AzureVectorImageSearch