Local LLM, Aspire and the Holidays
Building with Local LLMs and .NET Aspire: A Practical Guide

I went to Microsoft AI Tour Sydney at the beginning of December 2024 and attended a talk by Aaron Powell about Microsoft Aspire and using local LLM using Aspire. It was an eye opener for me as until then I always thought Aspire was about cloud and cloud only.
I have used LLM models locally before and even wrote a blog article about it (https://tjgokken.com/how-to-integrate-llama-3-in-your-c-projects-a-step-by-step-guide) but I used OllamaSharp. Needless to say, I was intrigued by this talk and I wanted to play with this technology a bit.
I like local LLMs because used for the right purpose they are pretty invaluable. Depending on how big you want to go with the model, you can get pretty accurate and fast outputs for their size, not to mention that they are free.
I did not want just another console application for this one. As I was searching for something interesting to do for this article, the idea came to me one night. I was talking to a friend and the conversation steered into pangrams. A pangram is a sentence where every letter of the alphabet is used at least once. Then there is the perfect pangram where every letter of the alphabet is used only once in a sentence but as you can imagine that is a very hard one. I thought it would be cool to make a little web app that generates pangrams for me using a local LLM.
It is not secret that I love Blazor WASM, but not all projects require it. Therefore, we are using Razor Pages is used for the front end. We will obviously use MS Aspire and for the AI component we will use Ollama (not OllamaSharp).
So, let’ begin by first looking into the architecture.
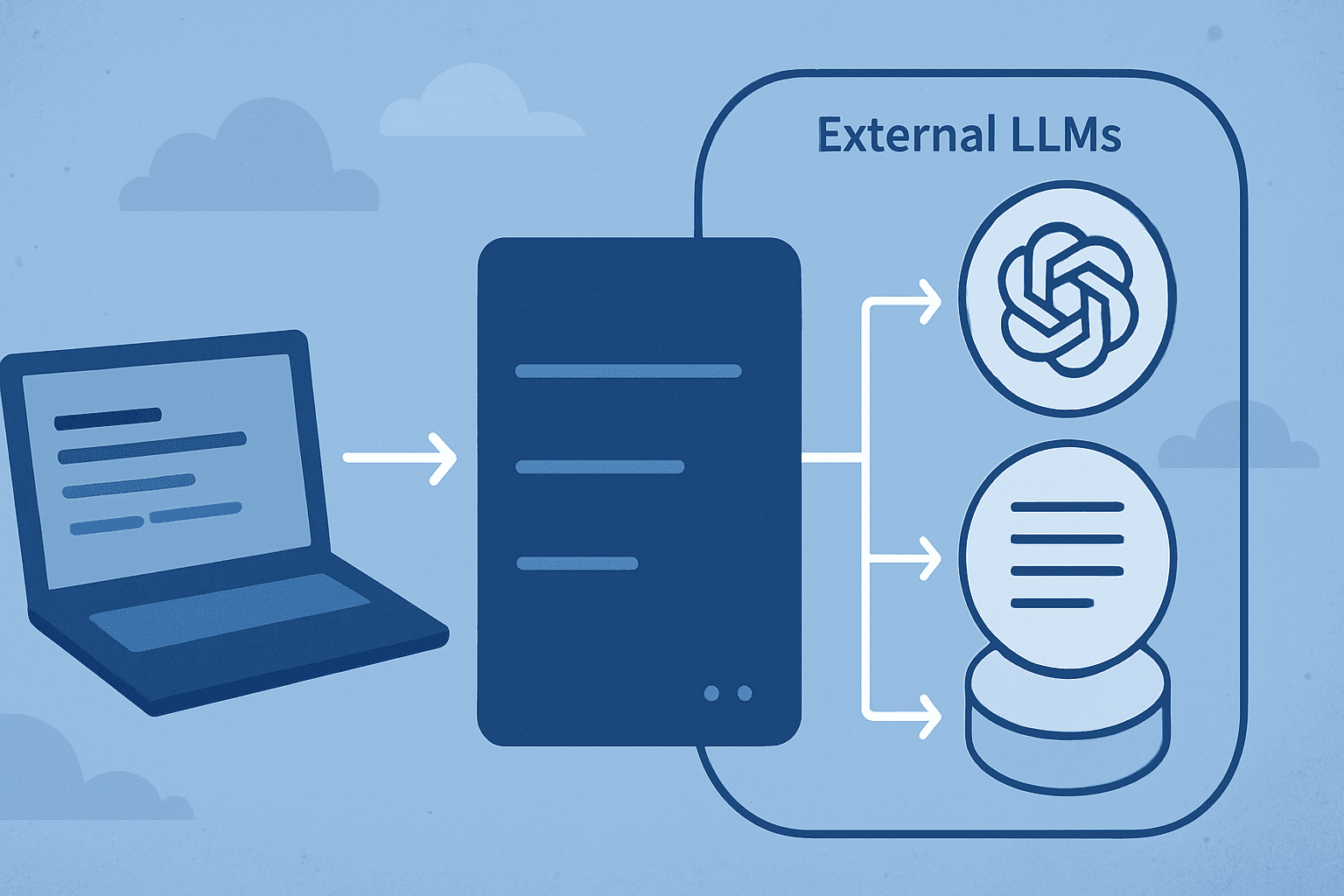
The Architecture
Here is a bird’s eye view of our solution:

We have 3 projects in our solution (HolidayPangram is our solution’s name):
AppHost: This is our startup project and is the orchestrator of our entire application. It starts up all our services in the correct order, sets up Ollama and configures our local LLM model, manages connections between services and provides Aspire dashboard for monitoring.
The key file in this project is Program.cs where we define how everything should run together. The Aspire configuration is surprisingly clean. Check this out:
var builder = DistributedApplication.CreateBuilder(args);
var ollama = builder.AddOllama("ollama")
.WithDataVolume();
var llama = ollama.AddModel("llama", "llama3");
builder.AddProject<Projects.HolidayPangram_Web>("pangram-web")
.WithReference(llama)
.WaitFor(llama);
await builder.Build().RunAsync();
See that? Just a few lines of code, and Aspire handles all the service orchestration for us. One gotcha though - notice how we use "HolidayPangram_Web" with an underscore? That's a quirk of Aspire you'll want to remember
The WithDataVolume() call makes sure our model data persists between restarts so we do not have to download the model from scratch every time we run the app, while WithOpenWebUI() gives us a nice interface for monitoring Ollama.
ServiceDefaults: This project contains some useful defaults for service configuration like telemetry, health checks, etc. While we do not need it for our solution at this time, I kept it because it provides a goo foundation if we want to add monitoring later and it handles some basic service configuration that we might need to replicate if we remove it.
If you look at the Extensions.cs class in this project, you will see that I left the namespace intact. Instead of pointing it to our project’s namespace, we are using Microsoft’s?:
namespace Microsoft.Extensions.Hosting;
This is called namespace lifting - a pattern where extensions are placed in the common Microsoft namespace to make them globally available without using additional using statements. If we were to move it to our project’s namespace, we, then, will have to use using statements whenever we want to use these extensions. This way, the code is kept cleaner.
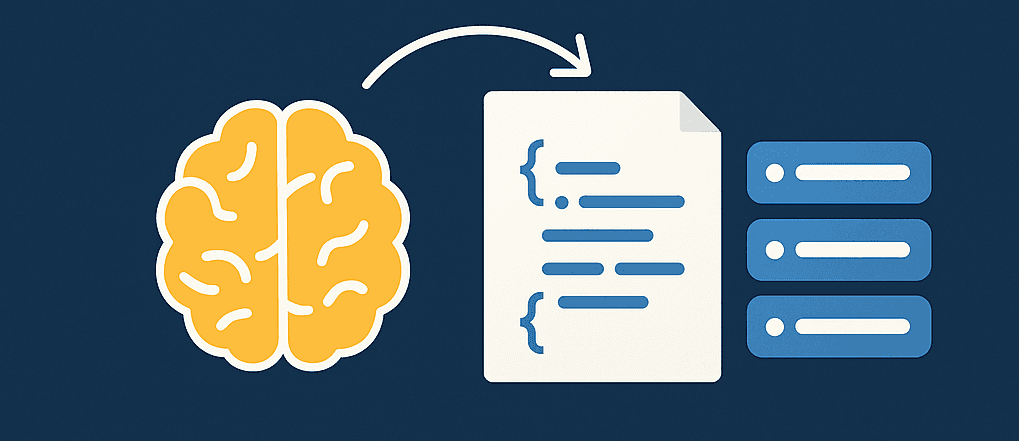
Web: This is our actual application where all the business logic lies. I used Razor Pages for UI because of its simplicity and for just plain CSS for the UI. It consists of a class called PangramService for generating pangrams. It connects to Ollama using the configuration from AppHost and then this service generates pangrams using the local language model.
Here is an flow view of the app:

And here is the code that generates pangrams:
public async Task<string> GeneratePangram(string theme)
{
try
{
var prompt = GetPrompt(theme);
var request = new ChatRequest
{
Model = "llama3",
Messages =
[
new Message { Role = "user", Content = prompt }
]
};
var response = new StringBuilder();
await foreach (var chunk in ollamaClient.ChatAsync(request))
if (chunk?.Message?.Content != null)
response.Append(chunk.Message.Content);
var pangram = response.Length > 0 ? response.ToString().Trim() : GetFallbackPangram(theme);
// is it a proper pangram?
return IsPangram(pangram) ? pangram : GetFallbackPangram(theme);
}
catch
{
return GetFallbackPangram(theme);
}
}
This method takes the theme as a string, either “Christmas” or “Easter”. It then gets the prompt from a static method in the same class, and initializes Ollama.
It then processes the response as a stream. It uses StringBuilder for efficient string concatenation.
Let’s hit the pause button and talk about the models for a second. When I first started, I thought "Let's use Phi since it's smaller and faster to download." But after testing, I found that Llama 3, despite being almost three times larger, gave noticeably better results for pangram generation. You can check your available models with this simple command:
ollama list
This will show you what you've got installed - in my case, both Phi and Llama 3.
$ ollama list
NAME ID SIZE MODIFIED
phi:latest e2fd6321a5fe 1.6 GB 2 days ago
llama3:latest 365c0bd3c000 4.7 GB 5 months ago
If for some reason we cannot get the response then our little app gets a fallback pangram which is a set of hard coded pangrams (generated by ChatGPT - I checked their accuracy using a Pangram Checker at https://planetcalc.com/6914/):
private readonly Dictionary<string, List<string>> _fallbackPangrams = new()
{
["christmas"] =
[
"Santa’s big fluffy reindeer joyfully zipped over quaint chimneys, making kids wish for extra presents",
"Jolly elves baked quick gingerbread treats, wrapping festive Xmas gifts near dazzling holiday lights",
"Jolly Santa zipped swiftly through frosty chimneys, making vibrant Xmas gifts and baking quick, warm pies"
],
["easter"] =
[
"Whimsical bunnies zigzagged through quiet gardens, joyfully hiding vibrant Easter eggs for excited kids to unwrap",
"Jolly kids quickly zigzagged through meadows, spotting vibrant Easter eggs wrapped in exquisite foil",
"Mixing bright chocolate eggs, quirky rabbits zigzagged through vibrant meadows while joyful kids unwrapped treats"
]
};
We also get a fallback pangram if the returned response is not a pangram. Here is how we check the response:
private static bool IsPangram(string text)
{
if (string.IsNullOrWhiteSpace(text))
return false;
var uniqueLetters = new HashSet<char>(text.ToLower().Where(c => c is >= 'a' and <= 'z'));
//Console.WriteLine($"Detected letters: {string.Join(", ", uniqueLetters.OrderBy(c => c))}");
var missingLetters = new HashSet<char>("abcdefghijklmnopqrstuvwxyz")
.Except(uniqueLetters)
.OrderBy(c => c)
.ToList();
if (missingLetters.Any())
{
//Console.WriteLine($"Missing letters: {string.Join(", ", missingLetters)}");
return false;
}
return uniqueLetters.Count == 26;
}
I left the console debugging statements in case you want to see that information.
In this code, we use a hash set to find the letters. Alternatively we could have used a .DistinctBy but a hash set gets the unique values in one go and therefore more performant.
The Application
When you run the application, Aspire dashboard fires up and you can see all of the components starting up. At the very beginning, you may need to wait a bit because if the model you are using is not already on your machine, then you will need to download it. Once it's downloaded, subsequent starts are much quicker. The Aspire dashboard is super helpful here because it shows you exactly what's happening with your services.

And when you click on the link for your web app, you see the following:

OK, not too bad. I am using standard CSS for the UI and while it can be improved, it serves my purposes just fine. Using a framework like Tailwind would take away from the focus of the app.
Lessons Learnt
First, with Ollama and Aspire make local AI development very easy and straightforward - it's basically "download and go." And the best part? No API costs or rate limits to worry about.
Service orchestration with Aspire is remarkably hands-off. Once you set up your dependencies correctly, Aspire manages the lifecycle of your services beautifully.
Second, model management is more straightforward than you might expect. Models are cached locally after the first download, and Ollama handles multiple models simultaneously without breaking a sweat. But you need to be patient during that first run - downloading a 4.7GB model takes time!
The resource usage patterns are worth noting too. While Phi runs comfortably with about 2GB of memory, Llama 3 needs around 6GB. Make sure your development machine can handle this before you start.
Want to try this yourself? The setup process is straightforward: create an Aspire starter app, install Ollama on your machine, add those Community Toolkit packages I mentioned, and you're mostly there. Just make sure you've got enough disk space for the models - Llama 3 isn't tiny!
This is just the beginning, really. There's so much more we could do - try different models, optimize prompts, add caching, maybe even let users switch between models on the fly. But for now, we've got a solid foundation for local AI development with .NET.
What do you think? Have you tried running AI models locally? I'd love to hear about your experiences, especially if you've played with different models or found other interesting ways to integrate them with .NET applications.
You can find the source code at https://github.com/tjgokken/HolidayPangram